Click here Try GLM for Yourself
Z.ai’s latest model is closing the gap with Western frontier AI faster than the industry expected. The hardware story is worse.
Z.ai released GLM-5.1 on March 27, 2026, making it available to all GLM Coding Plan subscribers. The announcement landed on X with 1.2 million views and was met, in most Western AI circles, with the particular silence reserved for news people aren’t sure how to contextualize. That silence is worth examining, because the model deserves a cleaner read than it’s getting.
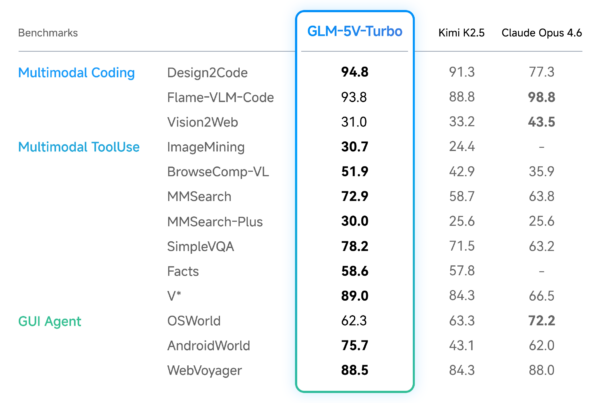
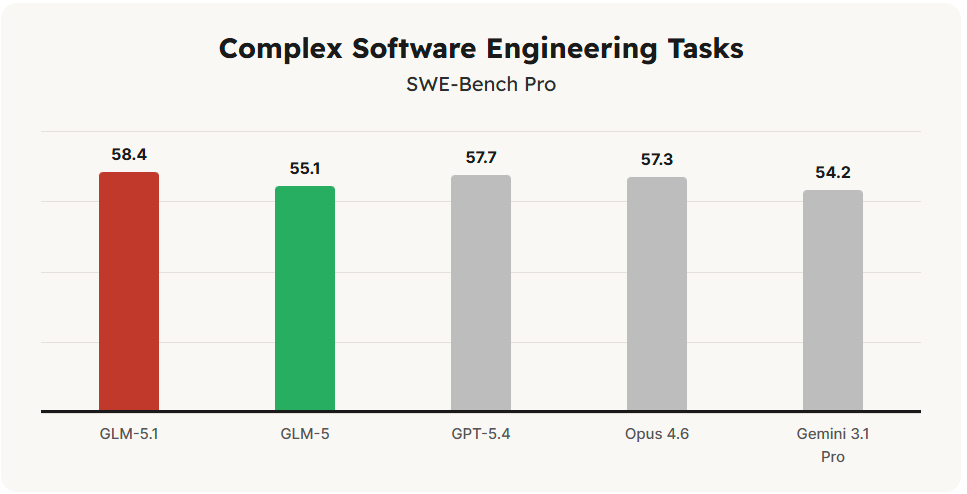
Using Claude Code as the evaluation framework, GLM-5.1 scored 45.3 on Z.ai’s internal coding benchmark. Claude Opus 4.6 scored 47.9. The gap is 2.6 points. In the world of LLM benchmarks, where labs regularly argue about fractions of a percentage point, a 2.6 point gap between an open-weights model from a Chinese lab and the best coding model Anthropic has ever shipped is not a gap. It’s a statement.
The instinct from the incumbent side will be to poke at the methodology. Z.ai chose Claude Code as the testing environment, which does give Claude a structural familiarity advantage because the tooling was built for it. That’s a noteworthy detail that Z.ai chose to lean into rather than obscure, suggesting a level of confidence in the result that isn’t common in benchmark marketing. They ran their model through the competitor’s house and still nearly won. That’s the point they’re making, and it lands.
The Five-Week Problem
What the benchmark score doesn’t capture is the velocity behind it, which is the part that should actually be keeping people up at night.
GLM-5 shipped in February 2026 with a coding evaluation score of 35.4. Five weeks later, GLM-5.1 scored 45.3. That is a 28% improvement with no architectural changes for the same base model, better post-training.
Think about what that means operationally. Z.ai didn’t go back and redesign the model. They didn’t train from scratch on new data. They refined their alignment pipeline and the supervised fine-tuning, the reinforcement learning stages, the distillation process — and extracted 28% more coding performance out of the same weights. That is a pure execution problem, and they solved it in a month.
Western labs are not moving at that speed on post-training iteration. They’re moving fast, but the public release cadence doesn’t reflect the kind of rapid-fire incremental improvement Z.ai just demonstrated. Whether that’s a structural difference in how they operate, a difference in organizational pressure, or simply a function of having more recent institutional memory of what it’s like to be behind. GLM-5.1 exists, and it’s nearly as good as Opus at coding, and it will be open source.
The Hardware Story Nobody Has a Good Response To
GLM-5 and GLM-5.1 were trained entirely on 100,000 Huawei Ascend 910B chips. No Nvidia hardware was used at any stage of training.
This should be treated as a significant geopolitical development. It is mostly being treated as a technical footnote.
The architecture of U.S. AI export policy rests on a theory: restrict access to advanced compute, restrict access to frontier model training, maintain a lead by controlling the inputs. It is a defensible theory. It has also now produced a situation where a Chinese AI lab that IPO’d on the Hong Kong stock exchange in January 2026 at a $31.3 billion valuation and has trained a frontier-adjacent model on entirely domestic hardware, released it as open weights under MIT license, and is offering API access for ten dollars a month.
The export controls may have slowed this by a year. Maybe two. But the idea that they would prevent it was always optimistic, and the evidence is now public and benchmarked. There is no clean response to this from a policy standpoint. You can’t un-release a model. You can’t revoke weights that are already on HuggingFace. The Huawei Ascend ecosystem exists, it runs frontier training workloads, and the next version of every major Chinese model will also be trained on it.
What makes this particularly uncomfortable is that the Ascend 910B is not supposed to be competitive with H100s for training at this scale. The received wisdom was that Chinese labs could perhaps train smaller, more efficient models on domestic hardware but would hit a wall when trying to scale. GLM-5 runs 744 billion parameters with 40 billion active, trained on 28.5 trillion tokens. That is not a small model. That is not hitting a wall. That is operating at a scale that was supposed to be off-limits without Nvidia silicon, and it produced a result that is within three points of GPT-5.2 on SWE-bench.
The policy community needs to update its model. The technical community already has.
What the Model Actually Does Well
On SWE-bench Verified, GLM-5.1 scores 77.8%. Claude Opus 4.6 scores 80.8%. GPT-5.2 scores 80.0%. Three points separates GLM-5.1 from the two best closed-source coding models in the world. For individual developers, that gap is invisible in day-to-day work. For enterprises with specific, high-stakes technical requirements, it might matter. But for the median software team shipping product.
On Vending Bench 2, which measures sustained long-horizon planning by requiring a model to operate a simulated vending machine business over a full year, GLM-5 ranks first among open-source models and approaches Claude Opus 4.5. That benchmark doesn’t get as much press as SWE-bench, but it’s arguably more relevant to real agentic deployments. Running an agent loop for thirty seconds is easy. Running one for an hour without drifting, losing state, or making cascading bad decisions is the actual problem. GLM-5 is apparently good at this.
GLM-5 also integrates DeepSeek Sparse Attention, which substantially cuts deployment cost while preserving long-context capacity. Z.ai is not building in a vacuum. They are pulling the best ideas from across the open-source ecosystem including from DeepSeek, another Chinese lab that rattled the industry earlier this year and assembling them into a coherent product. That’s not plagiarism. That’s how engineering works. The Western labs do it too. The difference is that Z.ai is doing it faster right now.
Where It Still Falls Short
GLM-5.1 is a coding and agentic model. It is not pretending to be anything else, which is actually a point in its favor.
Claude Opus 4.6 supports a one million token context window. GLM-5.1 caps at 200K. For any use case that requires sustained context across very long sessions for deep legal document review, large codebase analysis, long multi-session agentic work and that gap is real and not easily dismissed. 200K is generous for most tasks. It is not enough for all of them.
On complex reasoning and multimodal tasks, Opus retains a meaningful edge. GLM-5.1 was not built to be the best at everything. It was built to be nearly as good as the best at coding for a tenth of the price, and that is what it is.
The Market Question
The GLM Coding Plan runs $10 per month standard pricing. Claude Max runs $100. For a developer choosing between 94% of Opus performance at $10 versus 100% at $100, the math is not complicated. Most developers do not need the last 6%. They need reliable, fast, accurate code generation that fits inside a budget. GLM-5.1 answers that question directly.
The integration story is also deliberately frictionless. GLM-5.1 is fully compatible with Claude Code. Switching requires changing an API endpoint. Nothing else. Z.ai built on-ramp specifically calibrated for Claude’s user base. They are not asking developers to change their workflow. They are asking developers to change one line of configuration. That is a well-designed competitive move.
The weights are coming. Li Zixuan confirmed open-source release with the kind of brevity that suggests it’s not a question: “Don’t panic. GLM-5.1 will be open source.” Once those weights land, the conversation shifts again. A 94%-of-Opus coding model running locally on enterprise hardware, under MIT license, with no data leaving the building so that is a different value proposition than any cloud API can match. For law firms, medical practices, defense contractors, anyone for whom the data sovereignty pitch is not optional then this becomes a serious evaluation.
Broader Points
The Western AI narrative has been running on a particular story for two years. Frontier AI is expensive, closed, and American. Open-source models are impressive but not competitive. Chinese labs are catching up but not there yet.
GLM-5.1, alongside Qwen 3.5 and DeepSeek, represents a class of open-weights models that are now operating at or near frontier-level performance on specific benchmarks. The gap between the best closed-source American models and the best open-weights Chinese models is now measured in single digits on the benchmarks that matter to real engineers. That gap will be zero within the year on at least some dimensions. Probably sooner.
None of this means Anthropic or OpenAI are in trouble next quarter. They have ecosystems, trust, enterprise contracts, and capability advantages that don’t evaporate because one benchmark moved. But the story that Western labs can maintain a comfortable, durable lead based on compute access and organizational advantage and that story has a shorter shelf life than it did in January.
GLM-5.1 is one data point. The problem is that the data points keep pointing the same direction, arriving faster than expected, and being trained on hardware that wasn’t supposed to work this well.
At some point, a trend is just the situation.