Click here Try GLM for Yourself
Most “multimodal” models can look at an image and tell you what’s in it. Congratulations. So can a golden retriever.
GLM-5V-Turbo does something more interesting. It’s Z.AI’s first model built specifically for vision-based coding tasks and not just vision, not just coding, but the intersection where most models fall apart.
What It Is
GLM-5V-Turbo is a vision-language model with a 200K context window and up to 128K output tokens. It takes images, video, text, and files as input. It outputs text, specifically, code, plans, and structured responses grounded in what it can see.
The positioning is “multimodal coding foundation model.” That’s not marketing fluff. The design choices back it up.
It uses a custom vision encoder called CogViT paired with an MTP (multi-token prediction) architecture optimized for inference speed. The goal was to keep a smaller parameter count without gutting performance. Based on benchmark results, they largely pulled it off.
The Four Engineering Bets
Z.AI made specific technical decisions that differentiate this model. They’re worth understanding.
Native Multimodal Fusion. Visual and text training weren’t stitched together post-hoc. The fusion happens from pretraining through post-training. This matters because most VLMs treat vision as a bolt-on. When vision is native, the model reasons across modalities instead of translating between them.
30+ Task Joint Reinforcement Learning. During RL training, the model was optimized across more than 30 task types simultaneously. STEM, GUI agents, video, grounding, coding all at once. Joint RL tends to produce more robust generalization than task-specific fine-tuning. The tradeoff is complexity. Z.AI appears to have eaten that complexity so you don’t have to.
Agentic Data Construction. Agent data is scarce and hard to verify. Z.AI built a multi-level, verifiable data pipeline and injected what they call “agentic meta-capabilities” during pretraining. Translation: the model learned to predict and execute actions early, not as an afterthought.
Expanded Multimodal Toolchain. The model can use tools that involve visual input, a box drawing, screenshots, webpage reading with image understanding. This extends agent loops beyond pure text into actual visual interaction. Relevant if your workflows involve real interfaces rather than imaginary ones.
What It’s Built to Do
Frontend Recreation from Screenshots. Send it a design mockup. It reads the layout, color palette, component hierarchy, and interaction logic and then generates a runnable frontend project. For wireframes it reconstructs structure. For high-fidelity designs it aims for pixel-level accuracy.
The demo output in the docs shows it taking a two-screen mobile mockup and generating all four pages, including ones not explicitly shown. That’s inference, not just imitation.
Autonomous Website Exploration. Paired with Claude Code or OpenClaw, it can browse a live website, map page transitions, collect visual assets and interaction details, then generate code from exploration, not just from a static screenshot. The docs describe this as upgrading from “recreating from a screenshot” to “recreating through autonomous exploration.” That’s a meaningful capability jump.
Code Debugging from Screenshots. Drop in a screenshot of a broken UI. It identifies rendering issues, layout misalignment, component overlap, color mismatches and generates fix code. Useful for anyone who has spent 45 minutes staring at a CSS bug that a fresh pair of eyes would spot in seconds. The model is the fresh eyes.
GUI Agent Tasks via OpenClaw. When integrated with OpenClaw, it handles complex real-world tasks combining visual perception, planning, and execution. Webpage layouts, GUI elements, chart data — it processes all of it as part of an action loop.
Click here Try GLM for Yourself
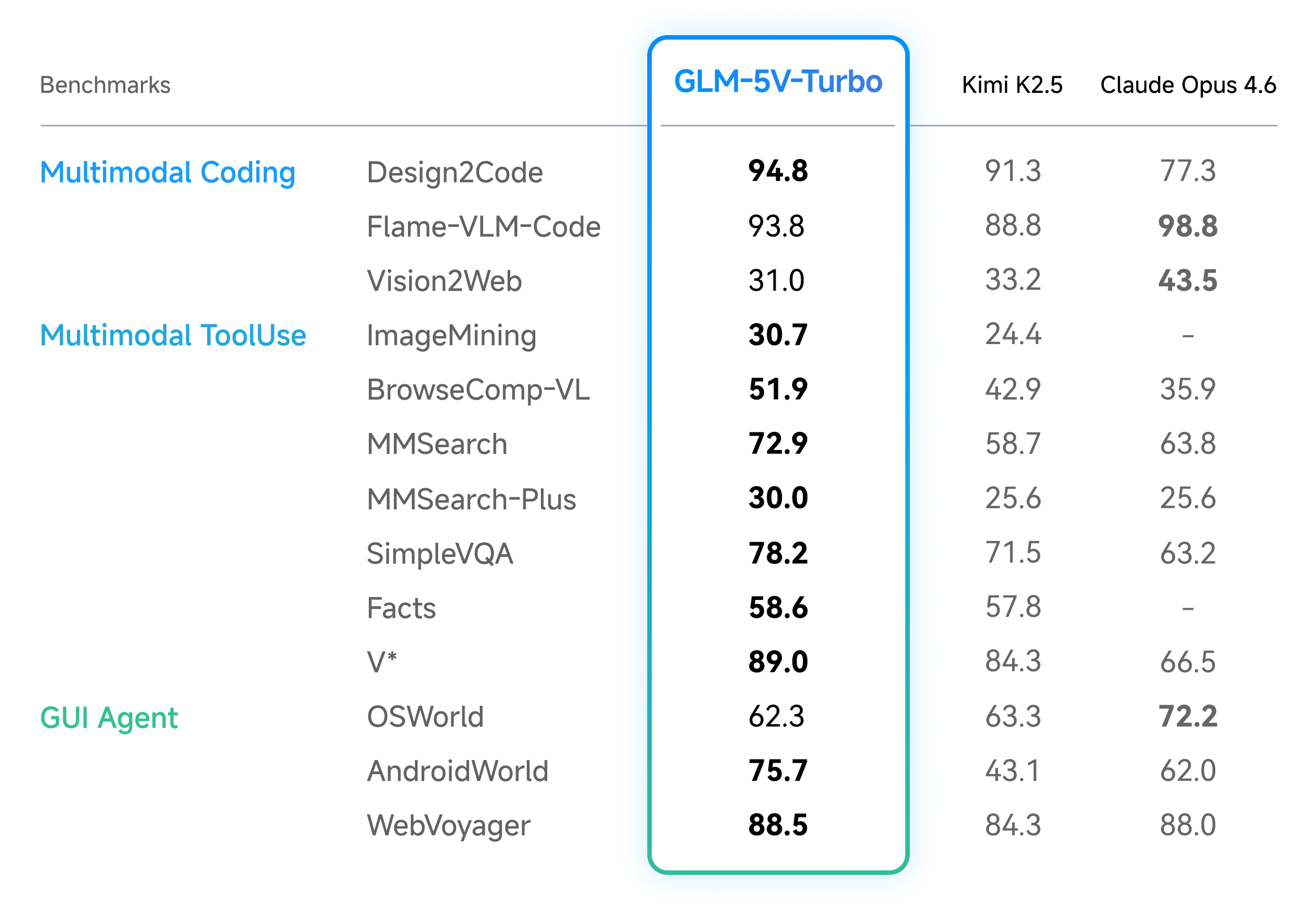
The Benchmarks
On multimodal coding benchmarks, GLM-5V-Turbo posted leading results in design-to-code, visual code generation, and multimodal retrieval. It also performed well on AndroidWorld and WebVoyager, which test agents operating in real GUI environments. Those are harder tests than academic benchmarks. Real GUIs are messy.
On pure-text coding benchmarks, Backend, Frontend, Repo Exploration in CC-Bench-V2 the performance held up. Adding visual capability didn’t cannibalize text-only coding ability. That’s not guaranteed. Plenty of multimodal models sacrifice text performance for vision gains. This one didn’t.
The model also scored well on PinchBench, ClawEval, and ZClawBench, which evaluate agent task execution quality specifically.
Official Skills
Z.AI ships a set of pre-built Skills available on ClawHub:
Image Captioning — identifies objects, relationships between objects, scene context, and actions. Goes beyond label detection into actual scene understanding.
Visual Grounding — given a natural-language description, locates the corresponding region in an image with bounding box precision. Useful for fine-grained analysis and interactive workflows.
Document-Grounded Writing — extracts key information from PDFs and Word files, then generates structured text grounded in the document. Report generation, news writing, proposal drafting.
Resume Screening — reads resumes, compares against job requirements, extracts education, experience, and skills, then ranks candidates. Recruiting automation that actually understands the document rather than keyword matching.
Prompt Generation — analyzes reference images or videos and generates structured prompts for image and video generation models. Meta-capability: using vision to improve generation inputs.
Integration
The API endpoint is standard: POST https://api.z.ai/api/paas/v4/chat/completions with model set to glm-5v-turbo. Supports streaming. Thinking mode is available and toggleable.
SDK support covers Python (zai-sdk), Java (Maven/Gradle), and cURL. The Python SDK install is a single pip command. The API structure mirrors OpenAI-compatible patterns if you’ve worked with those before.
Thinking mode is enabled by passing "thinking": {"type": "enabled"} in the request body. Worth enabling for complex visual reasoning tasks. Skip it for latency-sensitive pipelines.
Give It a Try
GLM-5V-Turbo is a focused model. It’s not trying to win every benchmark. It’s built for a specific workflow loop: see a visual environment, plan what to do, execute code. That loop is increasingly relevant as agentic systems move into real interfaces rather than sandboxed APIs.
The smaller model size with competitive benchmark performance is the interesting bet. If it holds up under real workloads, it becomes a cost-efficient option for vision-heavy coding pipelines.
Worth evaluating if your stack involves frontend generation, GUI automation, or any workflow where the input is a screenshot and the output needs to be code.

